Mining the Social Web, 2nd Edition¶
Chapter 2: Mining Facebook: Analyzing Fan Pages, Examining Friendships, and More¶
This IPython Notebook provides an interactive way to follow along with and explore the numbered examples from Mining the Social Web (2nd Edition). The intent behind this notebook is to reinforce the concepts from the sample code in a fun, convenient, and effective way. This notebook assumes that you are reading along with the book and have the context of the discussion as you work through these exercises.
In the somewhat unlikely event that you've somehow stumbled across this notebook outside of its context on GitHub, you can find the full source code repository here.
Copyright and Licensing¶
You are free to use or adapt this notebook for any purpose you'd like. However, please respect the Simplified BSD License that governs its use.
Facebook API Access¶
Facebook implements OAuth 2.0 as its standard authentication mechanism, but provides a convenient way for you to get an access token for development purposes, and we'll opt to take advantage of that convenience in this notebook. For details on implementing an OAuth flow with Facebook (all from within IPython Notebook), see the _AppendixB notebook from the IPython Notebook Dashboard.
For this first example, login to your Facebook account and go to https://developers.facebook.com/tools/explorer/ to obtain and set permissions for an access token that you will need to define in the code cell defining the ACCESS_TOKEN variable below.
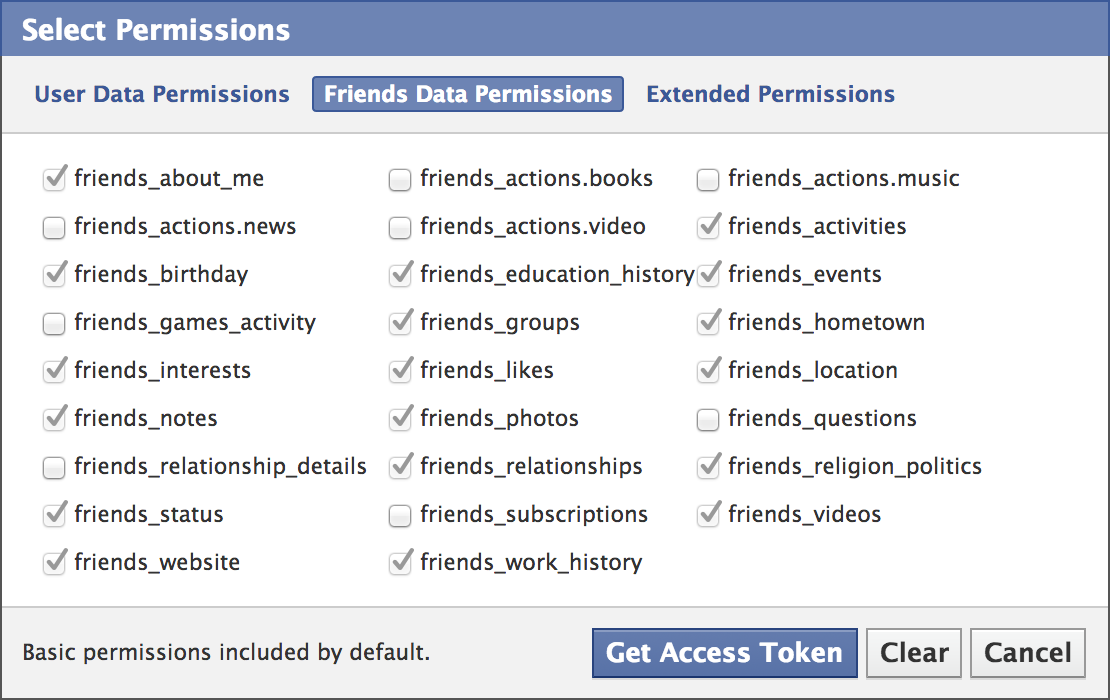
Be sure to explore the permissions that are available by clicking on the "Get Access Token" button that's on the page and exploring all of the tabs available. For example, you will need to set the "friends_likes" option under the "Friends Data Permissions" since this permission is used by the script below but is not a basic permission and is not enabled by default.
# Copy and paste in the value you just got from the inline frame into this variable and execute this cell.
# Keep in mind that you could have just gone to https://developers.facebook.com/tools/access_token/
# and retrieved the "User Token" value from the Access Token Tool
ACCESS_TOKEN = ''
Example 1. Making Graph API requests over HTTP¶
import requests # pip install requests
import json
base_url = 'https://graph.facebook.com/me'
# Get 10 likes for 10 friends
fields = 'id,name,friends.limit(10).fields(likes.limit(10))'
url = '%s?fields=%s&access_token=%s' % \
(base_url, fields, ACCESS_TOKEN,)
# This API is HTTP-based and could be requested in the browser,
# with a command line utlity like curl, or using just about
# any programming language by making a request to the URL.
# Click the hyperlink that appears in your notebook output
# when you execute this code cell to see for yourself...
print url
# Interpret the response as JSON and convert back
# to Python data structures
content = requests.get(url).json()
# Pretty-print the JSON and display it
print json.dumps(content, indent=1)
Note: If you attempt to run a query for all of your friends' likes and it appears to hang, it is probably because you have a lot of friends who have a lot of likes. If this happens, you may need to add limits and offsets to the fields in the query as described in Facebook's field expansion documentation. However, the facebook library that we'll use in the next example handles some of these issues, so it's recommended that you hold off and try it out first. This initial example is just to illustrate that Facebook's API is built on top of HTTP.
A couple of field limit/offset examples that illustrate the possibilities follow:
fields = 'id,name,friends.limit(10).fields(likes)' # Get all likes for 10 friends
fields = 'id,name,friends.offset(10).limit(10).fields(likes)' # Get all likes for 10 more friends
fields = 'id,name,friends.fields(likes.limit(10))' # Get 10 likes for all friends
fields = 'id,name,friends.fields(likes.limit(10))' # Get 10 likes for all friends
Example 2. Querying the Graph API with Python¶
import facebook # pip install facebook-sdk
import json
# A helper function to pretty-print Python objects as JSON
def pp(o):
print json.dumps(o, indent=1)
# Create a connection to the Graph API with your access token
g = facebook.GraphAPI(ACCESS_TOKEN)
# Execute a few sample queries
print '---------------'
print 'Me'
print '---------------'
pp(g.get_object('me'))
print
print '---------------'
print 'My Friends'
print '---------------'
pp(g.get_connections('me', 'friends'))
print
print '---------------'
print 'Social Web'
print '---------------'
pp(g.request("search", {'q' : 'social web', 'type' : 'page'}))
Example 3. Results for a Graph API query for Mining the Social Web¶
# Get an instance of Mining the Social Web
# Using the page name also works if you know it.
# e.g. 'MiningTheSocialWeb' or 'CrossFit'
mtsw_id = '146803958708175'
pp(g.get_object(mtsw_id))
Example 4. Querying the Graph API for Open Graph objects by their URLs¶
# MTSW catalog link
pp(g.get_object('http://shop.oreilly.com/product/0636920030195.do'))
# PCI catalog link
pp(g.get_object('http://shop.oreilly.com/product/9780596529321.do'))
Example 5. Comparing likes between Coke and Pepsi fan pages¶
# Find Pepsi and Coke in search results
pp(g.request('search', {'q' : 'pepsi', 'type' : 'page', 'limit' : 5}))
pp(g.request('search', {'q' : 'coke', 'type' : 'page', 'limit' : 5}))
# Use the ids to query for likes
pepsi_id = '56381779049' # Could also use 'PepsiUS'
coke_id = '40796308305' # Could also use 'CocaCola'
# A quick way to format integers with commas every 3 digits
def int_format(n): return "{:,}".format(n)
print "Pepsi likes:", int_format(g.get_object(pepsi_id)['likes'])
print "Coke likes:", int_format(g.get_object(coke_id)['likes'])
Example 6. Querying a page for its "feed" and "links" connections¶
pp(g.get_connections(pepsi_id, 'feed'))
pp(g.get_connections(pepsi_id, 'links'))
pp(g.get_connections(coke_id, 'feed'))
pp(g.get_connections(coke_id, 'links'))
Example 7. Querying for all of your friends' likes¶
# First, let's query for all of the likes in your social
# network and store them in a slightly more convenient
# data structure as a dictionary keyed on each friend's
# name. We'll use a dictionary comprehension to iterate
# over the friends and build up the likes in an intuitive
# way, although the new "field expansion" feature could
# technically do the job in one fell swoop as follows:
#
# g.get_object('me', fields='id,name,friends.fields(id,name,likes)')
#
# See Appendix C for more information on Python tips such as
# dictionary comprehensions
friends = g.get_connections("me", "friends")['data']
likes = { friend['name'] : g.get_connections(friend['id'], "likes")['data']
for friend in friends }
print likes
Example 8. Calculating the most popular likes among your friends¶
# Analyze all likes from friendships for frequency
# pip install prettytable
from prettytable import PrettyTable
from collections import Counter
friends_likes = Counter([like['name']
for friend in likes
for like in likes[friend]
if like.get('name')])
pt = PrettyTable(field_names=['Name', 'Freq'])
pt.align['Name'], pt.align['Freq'] = 'l', 'r'
[ pt.add_row(fl) for fl in friends_likes.most_common(10) ]
print 'Top 10 likes amongst friends'
print pt
Example 9. Calculating the most popular categories for likes among your friends¶
# Analyze all like categories by frequency
friends_likes_categories = Counter([like['category']
for friend in likes
for like in likes[friend]])
pt = PrettyTable(field_names=['Category', 'Freq'])
pt.align['Category'], pt.align['Freq'] = 'l', 'r'
[ pt.add_row(flc) for flc in friends_likes_categories.most_common(10) ]
print "Top 10 like categories for friends"
print pt
Example 10. Calculating the number of likes for each friend and sorting by frequency¶
# Build a frequency distribution of number of likes by
# friend with a dictionary comprehension and sort it in
# descending order
from operator import itemgetter
num_likes_by_friend = { friend : len(likes[friend])
for friend in likes }
pt = PrettyTable(field_names=['Friend', 'Num Likes'])
pt.align['Friend'], pt.align['Num Likes'] = 'l', 'r'
[ pt.add_row(nlbf)
for nlbf in sorted(num_likes_by_friend.items(),
key=itemgetter(1),
reverse=True) ]
print "Number of likes per friend"
print pt
Example 11. Finding common likes between an ego and its friendships in a social network¶
# Which of your likes are in common with which friends?
my_likes = [ like['name']
for like in g.get_connections("me", "likes")['data'] ]
pt = PrettyTable(field_names=["Name"])
pt.align = 'l'
[ pt.add_row((ml,)) for ml in my_likes ]
print "My likes"
print pt
# Use the set intersection as represented by the ampersand
# operator to find common likes.
common_likes = list(set(my_likes) & set(friends_likes))
pt = PrettyTable(field_names=["Name"])
pt.align = 'l'
[ pt.add_row((cl,)) for cl in common_likes ]
print
print "My common likes with friends"
print pt
Example 12. Calculating the friends most similar to an ego in a social network¶
# Which of your friends like things that you like?
similar_friends = [ (friend, friend_like['name'])
for friend, friend_likes in likes.items()
for friend_like in friend_likes
if friend_like.get('name') in common_likes ]
# Filter out any possible duplicates that could occur
ranked_friends = Counter([ friend for (friend, like) in list(set(similar_friends)) ])
pt = PrettyTable(field_names=["Friend", "Common Likes"])
pt.align["Friend"], pt.align["Common Likes"] = 'l', 'r'
[ pt.add_row(rf)
for rf in sorted(ranked_friends.items(),
key=itemgetter(1),
reverse=True) ]
print "My similar friends (ranked)"
print pt
# Also keep in mind that you have the full range of plotting
# capabilities available to you. A quick histogram that shows
# how many friends.
plt.hist(ranked_friends.values())
plt.xlabel('Bins (number of friends with shared likes)')
plt.ylabel('Number of shared likes in each bin')
# Keep in mind that you can customize the binning
# as desired. See http://matplotlib.org/api/pyplot_api.html
# For example...
plt.figure() # Display the previous plot
plt.hist(ranked_friends.values(),
bins=arange(1,max(ranked_friends.values()),1))
plt.xlabel('Bins (number of friends with shared likes)')
plt.ylabel('Number of shared likes in each bin')
plt.figure() # Display the working plot
Example 13. Constructing a graph of mutual friendships¶
import networkx as nx # pip install networkx
import requests # pip install requests
friends = [ (friend['id'], friend['name'],)
for friend in g.get_connections('me', 'friends')['data'] ]
url = 'https://graph.facebook.com/me/mutualfriends/%s?access_token=%s'
mutual_friends = {}
# This loop spawns a separate request for each iteration, so
# it may take a while. Optimization with a thread pool or similar
# technique would be possible.
for friend_id, friend_name in friends:
r = requests.get(url % (friend_id, ACCESS_TOKEN,) )
response_data = json.loads(r.content)['data']
mutual_friends[friend_name] = [ data['name']
for data in response_data ]
nxg = nx.Graph()
[ nxg.add_edge('me', mf) for mf in mutual_friends ]
[ nxg.add_edge(f1, f2)
for f1 in mutual_friends
for f2 in mutual_friends[f1] ]
# Explore what's possible to do with the graph by
# typing nxg.<tab> or executing a new cell with
# the following value in it to see some pydoc on nxg
print nxg
Example 14. Finding and analyzing cliques in a graph of mutual friendships¶
# Finding cliques is a hard problem, so this could
# take a while for large graphs.
# See http://en.wikipedia.org/wiki/NP-complete and
# http://en.wikipedia.org/wiki/Clique_problem.
cliques = [c for c in nx.find_cliques(nxg)]
num_cliques = len(cliques)
clique_sizes = [len(c) for c in cliques]
max_clique_size = max(clique_sizes)
avg_clique_size = sum(clique_sizes) / num_cliques
max_cliques = [c for c in cliques if len(c) == max_clique_size]
num_max_cliques = len(max_cliques)
max_clique_sets = [set(c) for c in max_cliques]
friends_in_all_max_cliques = list(reduce(lambda x, y: x.intersection(y),
max_clique_sets))
print 'Num cliques:', num_cliques
print 'Avg clique size:', avg_clique_size
print 'Max clique size:', max_clique_size
print 'Num max cliques:', num_max_cliques
print
print 'Friends in all max cliques:'
print json.dumps(friends_in_all_max_cliques, indent=1)
print
print 'Max cliques:'
print json.dumps(max_cliques, indent=1)
Example 15. Serializing a NetworkX graph to a file for consumption by D3¶
from networkx.readwrite import json_graph
nld = json_graph.node_link_data(nxg)
json.dump(nld, open('resources/ch02-facebook/viz/force.json','w'))
Note: You may need to implement some filtering on the NetworkX graph before writing it out to a file for display in D3, and for more than dozens of nodes, it may not be reasonable to render a meaningful visualization without some JavaScript hacking on its parameters. View the JavaScript source in force.html for some of the details.
Example 16. Visualizing a mutual friendship graph with D3¶
from IPython.display import IFrame
from IPython.core.display import display
# IPython Notebook can serve files and display them into
# inline frames. Prepend the path with the 'files' prefix.
viz_file = 'files/resources/ch02-facebook/viz/force.html'
display(IFrame(viz_file, '100%', '600px'))